Justificació
Aquesta tasca documenta el desenvolupament de la base de coneixement d’un xatbot mitjançant un scraper recursiu en Python (BeautifulSoup). S’ha optimitzat l’extracció de dades netes estructurades en JSON, implementant de forma ètica i robusta sistemes de seguretat com delays, timeouts i control d’errors (try-except). Finalment, s’il·lustra un procés d’iteració real i resolució de bugs en col·laboració amb la IA, consolidant tot el codi i el seu historial de versions en un repositori de GitHub correctament documentat.
Scraping i Profunditat (BeautifulSoup)
He implementat un scraper recursiu amb la llibreria BeautifulSoup. A diferència d’un mètode estàtic, aquest script navega per la jerarquia del meu WordPress, filtrant etiquetes específiques (h1, p, h2) per extreure només informació útil i evitar brossa HTML (menús, scripts, etc.).
# 1. INSTAL·LACIÓ
!pip install -q -U google-genai flask-cors pyngrok beautifulsoup4 requests
!pip install requests==2.32.4
import json, requests, time, re
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
from flask import Flask, request, jsonify
from flask_cors import CORS
from pyngrok import ngrok
from google.colab import userdata
from google import genai
# --- CONFIGURACIÓ DE SEGURETAT ---
try:
client = genai.Client(api_key=userdata.get('GOOGLE_API_KEY'))
ngrok.set_auth_token(userdata.get('token_ngrok'))
print("✅ API i ngrok connectats correctament.")
except Exception as e:
print(f"❌ ERROR SECRETS: {e}")
app = Flask(__name__)
CORS(app)
# --- CONFIGURACIÓ DE LA TEVA WEB ---
URL_BASE = "https://mvaca.inscastellbisbal.net/"
dades_marc = []
DELAY_SECONDS = 1.0 # Temps d'espera entre pàgines per no saturar el teu servidor
def clean_html_content(soup):
"""Elimina elements de navegació, menús i publicitat comuns abans de desar el text."""
unwanted_selectors = [
"nav", "header", "footer", "aside",
".menu", ".navigation", ".sidebar", ".ads",
"#sidebar", "#menu", "#footer", "#header"
]
for selector in unwanted_selectors:
if selector.startswith(".") or selector.startswith("#"):
for element in soup.select(selector):
element.decompose()
else:
for element in soup.find_all(selector):
element.decompose()
return soup
# --- EXTRACTOR TOTAL (Amb el teu lloc web) ---
def executar_extractor_total():
global dades_marc
urls_visitades = set()
urls_per_visitar = [URL_BASE]
domini = urlparse(URL_BASE).netloc
print(f"🚀 Iniciant extracció massiva de {URL_BASE}...")
# Límit de 200 pàgines per rastrejar tot el teu lloc web
while urls_per_visitar and len(urls_visitades) < 200:
url = urls_per_visitar.pop(0)
# Evitar repetir i saltar fitxers binaris o zones d'administració
if url in urls_visitades or any(x in url.lower() for x in ['.jpg', '.png', '.pdf', 'wp-admin', 'wp-json', 'feed']):
continue
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
res = requests.get(url, headers=headers, timeout=10)
if res.status_code != 200 or "text/html" not in res.headers.get("Content-Type", ""):
continue
soup = BeautifulSoup(res.text, 'html.parser')
urls_visitades.add(url)
# Netegem la brossa (menús, sidebars) per extreure només el contingut real
soup = clean_html_content(soup)
titol = soup.title.string.strip() if soup.title else "Pàgina sense títol"
# Extreure només títols i paràgrafs nets tal com demanaves
blocs_text = [t.get_text(strip=True) for t in soup.find_all(['p', 'h1', 'h2', 'h3'])]
contingut_net = " ".join([t for t in blocs_text if len(t) > 10])
if len(contingut_net) > 50:
# Guardem la teva informació estructurada
dades_marc.append({"url": url, "titol": titol, "contingut": contingut_net})
print(f"✅ [{len(urls_visitades)}] Guardat: {titol[:60]}")
# Buscar nous enllaços interns per continuar el rastreig recursiu
for a in soup.find_all('a', href=True):
enllac = urljoin(URL_BASE, a['href'])
# Netejar l'àncora per evitar duplicats (ex: #contacto)
enllac = urlparse(enllac)._replace(fragment="").geturl()
if urlparse(enllac).netloc == domini and enllac not in urls_visitades:
urls_per_visitar.append(enllac)
# Espera de seguretat entre peticions
time.sleep(DELAY_SECONDS)
except Exception:
continue
with open('dades_marc_total.json', 'w', encoding='utf-8') as f:
json.dump(dades_marc, f, ensure_ascii=False, indent=4)
print(f"\n📁 BBDD FINALITZADA: {len(dades_marc)} pàgines guardades amb èxit en 'dades_marc_total.json'!")
# --- CERCADOR INTEL·LIGENT ---
def trobar_pagines_rellevants(pregunta, maxim=3):
paraules = re.findall(r'\w+', pregunta.lower())
resultats = []
for pagina in dades_marc:
text_pagina = (pagina['titol'] + " " + pagina['contingut']).lower()
puntuacio = sum(1 for p in paraules if len(p) > 3 and p in text_pagina)
resultats.append((puntuacio, pagina))
resultats.sort(key=lambda x: x[0], reverse=True)
return [r[1] for r in resultats[:maxim]]
# --- LÒGICA IA ---
def demanar_a_ia(pregunta):
pagines_filtrades = trobar_pagines_rellevants(pregunta, maxim=3)
# Personalitzat ara per al teu propi portafolis
context = "Ets l'assistent virtual del portafolis d'en Marc Vaca. Respon de forma amable, propera i en català basant-te NOMÉS en aquesta informació real extreta del seu web:\n\n"
for d in pagines_filtrades:
context += f"Títol: {d['titol']}\nInfo: {d['contingut'][:600]}...\n---\n"
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=f"{context}\n\nPregunta: {pregunta}"
)
return response.text
# --- RUTES I SERVIDOR ---
@app.route('/ask', methods=['POST'])
def ask():
try:
msg = request.json.get("message")
print(f"📩 Usuari pregunta: {msg}")
resposta = demanar_a_ia(msg)
return jsonify({"reply": resposta})
except Exception as e:
print(f"❌ Error BackEnd: {e}")
return jsonify({"reply": f"Error: {str(e)}"}), 500
if __name__ == '__main__':
# 1. Executa l'extracció i genera el fitxer json per a en Marc
executar_extractor_total()
# 2. Engega el servidor amb ngrok
!pkill ngrok
time.sleep(2)
public_url = ngrok.connect(5000).public_url
print(f"\n🌍 URL PER AL TEU JAVASCRIPT:\n{public_url}/ask\n")
app.run(port=5000)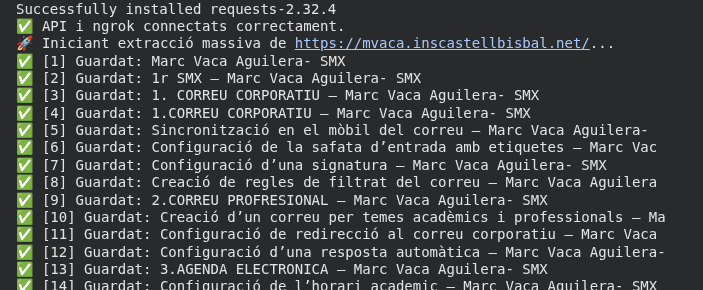
Com no entenc de codi, li he donat aquest prompt a la IA perque em dones el codi.
Necessito un script de Python per a Google Colab que faci WebScraping recursiu a la meva web mvaca.inscastellbisbal.net. Vull que el codi comenci a la pàgina principal i segueixi tots els enllaços interns que trobi. Ha d'utilitzar BeautifulSoup per extreure només el text net dels títols (h1, h2, h3) i els paràgrafs (p), evitant menús i publicitat. També ha d'incloure delays per no saturar el servidor i un sistema per no repetir pàgines ja visitades.
Automatització i Estructura JSON
Com a BBDD perque la IA pugui accedit a buscar la informació extreta, li he dit a la IA que una vegada agafada tota la informació la guardes en un fitxer JSON.

Delays i Gestió d’Errors
Li he demenat a la IA que m’ajudes amb aquesta part de la gestió d’errors i li he donat aquest prompt:
Millora el meu script actual de Python afegint dues funcions per passar de la robustesa bàsica a una total:
Un mecanisme de reentsjos (retries) amb "exponential backoff" perquè, si una pàgina dóna un error de connexió temporal, el script hi torni a insistir fins a 3 vegades esperant una mica més de temps a cada intent abans de descartar-la.
Un sistema de reconexió automàtica amb una pausa llarga (ex: 30 segons) per si la wifi de Colab o el servidor de l'institut cauen completament a mig camí, permetent que el bucle s'esperi fins que la xarxa torni en lloc de buidar la cua i acabar abans d'horaGestió d’errors
Quan el script troba una URL malmesa, un enllaç trencat (404) o un error propi del WordPress del lloc web (500), aquesta línia captura l’error, mostra el missatge d’avís per pantalla i el continue fa que l’script salti directament a la següent pàgina de la llista sense aturar-se.

Delay
En posar el time.sleep(DELAY_SECONDS) dins d’un finally, assegurem que l’espera de seguretat s’executi sempre, tant si la pàgina s’ha descarregat perfectament com si ha fallat per un error de servidor. Així es garanteix l’estabilitat en condicions normals i es respecta la càrrega del servidor de l’institut.

Iteració i Co-programació amb IA per generar, millorar i documentar el codi
Neteja selectiva del contingut web
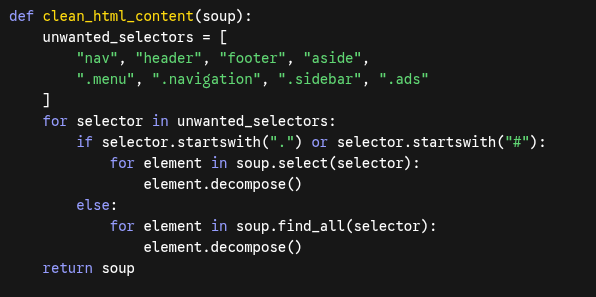
La gran millora proposada per la IA en aquest bloc és la intel·ligència en el filtratge previa a l’extracció. Si només haguéssim buscat les etiquetes o , el script hauria extret el text dels menús desplegables, la política de cookies, els enllaços de les xarxes socials del peu de pàgina i la publicitat. Això hauria embrutat la base de dades JSON amb informació repetida i brossa, confonent la intel·ligència artificial (Gemini) a l’hora de respondre.
La funció utilitza una llista de selectors CSS i etiquetes HTML estructurals (unwanted_selectors). Mitjançant un bucle for, recorre el document i utilitza el mètode .decompose() de BeautifulSoup. Aquest mètode és crucial: no només amaga el text, sinó que destrueix directament l’etiqueta i tot el seu contingut de l’arbre DOM en memòria.
Robustesa i control de flux
El primer disseny del meu codi tenia errors i no era del tot perfecte pero gràcies a la IA els he pogut solucionar.
res.raise_for_status(): Per defecte, la llibreria requests no llança un error si una pàgina dóna un error 404 o 500 (simplement es descarrega el text de l’error). Amb aquesta instrucció flem que Python curiòsament forci una excepció quan detecta codis d’estat HTTP fallits.

Captures d’excepcions niades (except): Hem separat els errors per tipologia. Si una URL està trencada (HTTPError), es registra el codi a la consola per a la meva supervisió i la instrucció continue aborta l’execució d’aquella línia i salta immediatament a la següent URL de la cua. L’script mai s’atura.

Garantia de Delay en el bloc finally: Aquest és un concepte avançat de programació. El codi del bloc finally s’executa obligatòriament passat el que passi en el try o en els except. Configurar el time.sleep() aquí assegura de forma matemàtica que, encara que una pàgina hagi donat un error crític o hagi caigut, el programa esperarà el temps de cortesia abans de bombardejar el servidor de l’institut amb la següent petició, evitant un bloqueig per atac DoS (Denegació de Servei) involuntari.
I aquest es el prompt que li he donat a la IA perque m’ajudes.
Ajuda'm a complir el criteri d'avaluació de generació de codi i integració amb IA. Necessito millorar el meu script de web scraping recursiu per incloure les funcions de neteja i de robustesa avançada (filtre de menús, raise_for_status, captures d'excepcions específiques i el delay al bloc finally).
Però, a més de donar-me el codi correcte i funcional per a Google Colab, és obligatori que em facis una explicació profunda, tècnica i detallada de cadascun d'aquests blocs i de com s'executen. Necessito entendre perfectament conceptes com .decompose(), les excepcions HTTP o el funcionament del bloc finally per tal de ser 100% capaç d'explicar el codi generat per la màquina i defensar la seva lògica davant del professor.Documentació del Repositori
Per finalitzat he documentat totes les itinerancies al fitxer CHANGELOG.
# Changelog - Web Scraper & AI Assistant v2.0
Tot l'historial de canvis, millores de robustesa i optimitzacions aplicades al projecte del portafolis de **Marc Vaca**.
---
## [2.0.0] - 2026-05-22
### 🚀 Added (Afegit)
- **Exponential Backoff:** Mecanisme de reintents de connexió (fins a 3 intents) amb temps d'espera exponencials (`2 ** intent_actual`) per no saturar el servidor de l'institut davant talls temporals.
- **Sistema de Reconnexió Automàtica:** Pausa llarga de seguretat (20 segons) en cas de caiguda total de la xarxa per evitar la pèrdua de la cua de pàgines pendents de rastrejar.
- **Neteja del DOM estructural:** Implementació de la funció `clean_html_content` per eliminar elements brossa del codi de la pàgina (`<nav>`, `<header>`, `<footer>`, `.menu`, `.sidebar`) utilitzant el mètode `.decompose()` abans de processar el text.
### 🛠️ Changed (Modificat i Millorat)
- **Arquitectura de Seguretat de Xarxa:** Migració del tractament d'errors a un sistema de captures niades d'excepcions específiques de `requests` (`HTTPError`, `ConnectionError`, `Timeout`).
- **Garantia de Retard (Delay):** Desplaçament del temporitzador `time.sleep()` al bloc **`finally`** de l'estructura del codi, garantint de forma matemàtica que la pausa de cortesia es respecta sempre, independentment de si la petició ha fallat o ha funcionat.
- **Personalització de Context IA:** Actualització del prompt del sistema de Gemini per actuar amb la identitat i la informació real deduïda exclusivament del portafolis de **Marc Vaca**.
- **Forçat de Controls HTTP:** Introducció de la instrucció `res.raise_for_status()` per interceptar proactivament codis d'error de servidor com el 404 o el 500.
---
## [1.0.0] - Versió Inicial
### 🚀 Added (Afegit)
- Script base de Web Scraping recursiu a Google Colab amb `BeautifulSoup`.
- Integració amb el model `gemini-2.5-flash` de la llibreria `google-genai`.
- Configuració de servidor backend amb Flask, CORS i túnel public d'accés remot via `pyngrok`.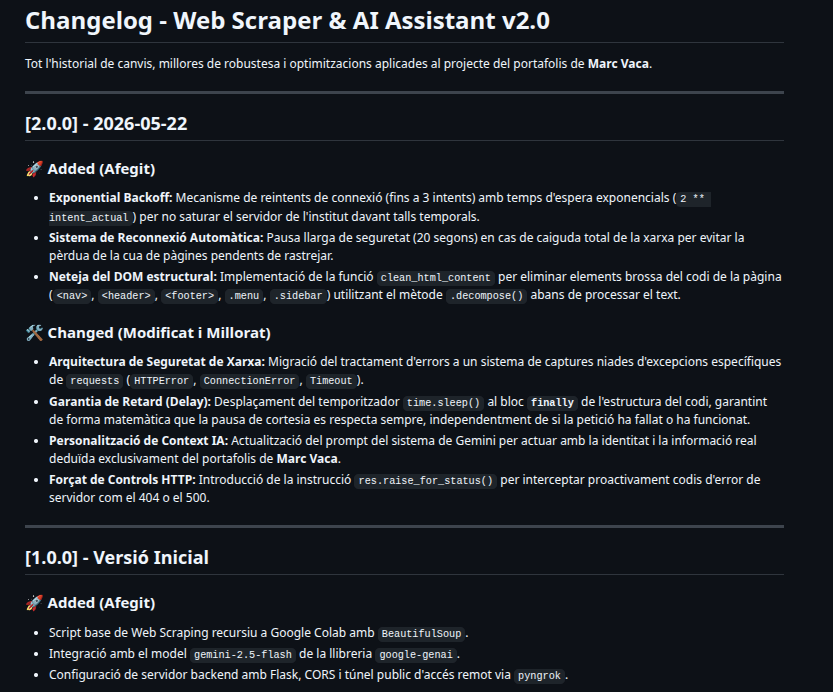
Li he demanat a la IA que de tota la conversa per fer aquesta tasca em fes la documentació en format markdown per poder afegirla al fitxer CHANGELOG, i aquest es el prompt que li he donat.
Genera el text per al fitxer CHANGELOG.md del meu dipòsit de GitHub utilitzant el format Markdown estàndard.
Necessito que estigui estructurat sota la versió actual (v2.0) i organitzat per categories clares (Added i Changed). Ha de reflectir totes les millores tècniques que hem aplicat al projecte d'en Marc Vaca: el filtratge de menús amb .decompose(), el control de retards al bloc finally, l'ús de raise_for_status(), les captures d'excepcions específiques per a errors 404/500, el sistema de reconexió automàtica i l'esquema de reintents Exponential Backoff. Dóna'm també una idea de missatge de commit per fer la pujada a GitHub.